Neuro-computations of Observational Learning vs. Experiential Learning
An Ice Cream Decision

- Bob gets chocolate again - last time he bought the chocolate one.
- You tried strawberry last time and didn’t like it.
- You assume Bob’s taste is similar to yours.
So, you choose chocolate—based on your own experience and Bob’s.
We face situations like this daily, where we blend firsthand experience with observed behavior. This study explores the neuro-computational basis of how we integrate observational and experiential learning.
A Social Pearl Hunting Task
To answer the question, I designed a social pearl hunting task, adapted from Charpentier et al., 2024 .
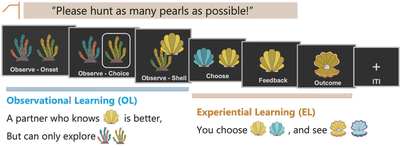
Participants gather pearls using two information sources:
- Observational learning (OL): Watch a partner choose a coral, then see the resulting shell. The partner knows which shell is better but can only choose corals.
- Experiential learning (EL): Choose a shell and receive direct feedback (pearl or not).
Disentangling Observational and Experiential Strategies
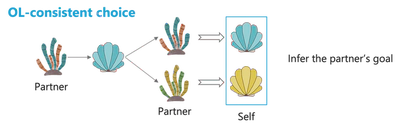
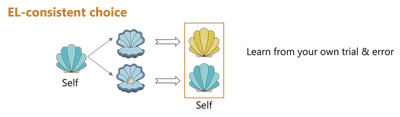
Reliability-based Arbitration
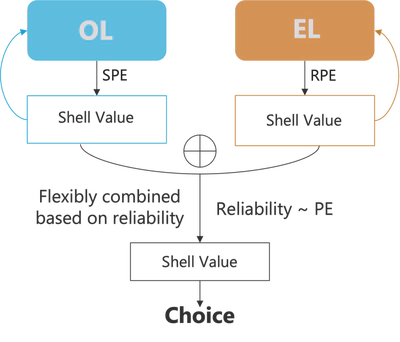
- Two systems compute shell values using prediction errors:
- State Prediction Error (SPE) for OL: mismatch between predicted and actual shell from the partner’s coral.
- Reward Prediction Error (RPE) for EL: mismatch between expected and actual reward.
- Values computed from the two systems are flexibly combined based on the reliability - a function of the prediction errors.
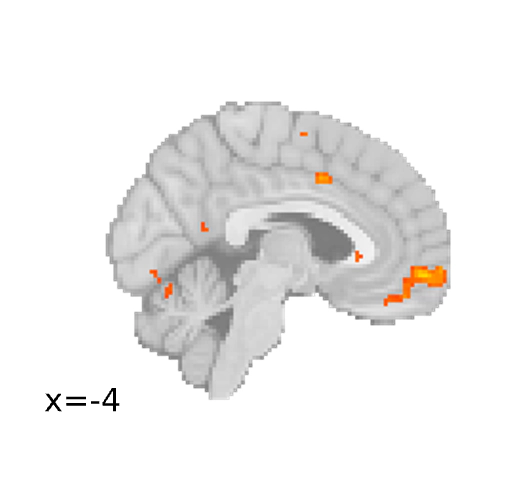
Neural Signatures of Decision Systems
Where does the brain compute these values?
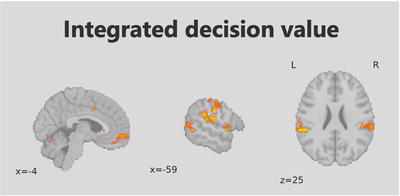
Using model-based fMRI analysis, we found the OL-based decision signal in the dorsal medial prefrontal cortex (dmPFC), temporal-parietal junction (TPJ), and superior temporal gyrus (STG). EL-based decision value in the ventromedial prefrontal cortex (vmPFC).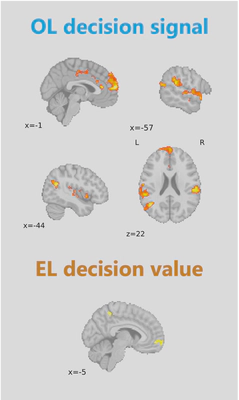
Conference Talk
On Apr 2024, I presented the above results at the Social Affective Neuroscience Society (SANS) annual meeting as a Data Blitz titled Neuro-computational Mechanism Of Reliability-based Arbitration Between Observational And Experiential Learning.